改變視頻行業的AI,快來了(但有點恐怖)
摘要
影視颶風的 Tim 測試了字節跳動的 Seedance 2.0 AI 影片生成模型,發現它在過去 AI 影片的三大致命弱點(大範圍運鏡、分鏡連續性、音畫匹配)上都有質的飛躍。更恐怖的是,模型僅靠一張臉部照片就能自動匹配該人的聲音,且對訓練數據中的場景具有空間記憶能力。Tim 認為傳統影視流程距離被 AI 海嘯沖走,已經進入倒計時。
重點筆記
態度轉變
Tim 坦言自己過去對 AI 模型的態度是「哦又發布了→炒概念→體驗不好→翻篇」,但 Seedance 2.0 的演示讓他態度徹底轉變。蜜雪冰城大戰外企咖啡店的生成影片精細度遠超以往。

痛點一:大範圍攝影機運動
過去 AI 影片在大範圍運鏡時會「破功」,是識別 AI 影片的主要方式。Seedance 2.0 測試中,僅用文本 + 圖片就生成了大範圍運鏡效果,Tim 評價「震撼」。

過去我們鑑別 AI 視頻是看攝影機運動假不假,這種方式已經基本上確定是失效的了。
痛點二:分鏡的連續性
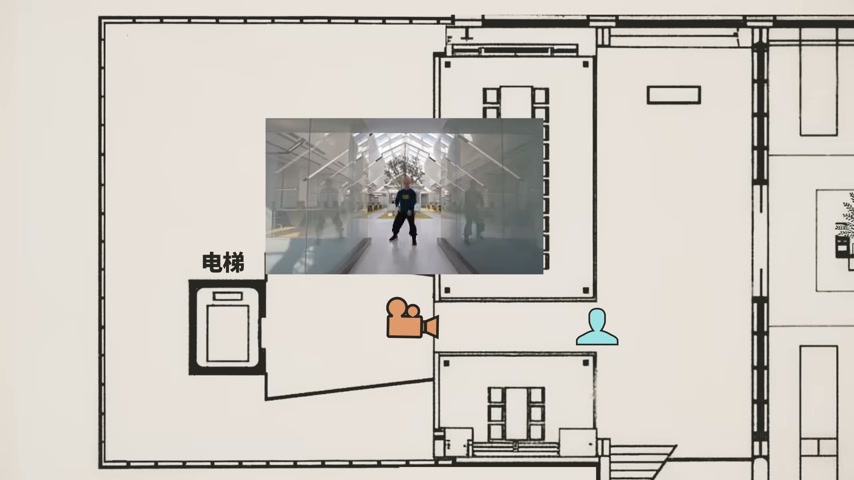
過去 AI 分鏡「為了切而切」,最多給特寫 + 全景,和真人導演的視聽語言有明顯區別。Tim 用俯視圖分析 AI 生成的機位變化,發現:
- 不只是給特寫,而是有明確的角度切換
- 存在導演意圖——不斷改變攝影機位置和視角,引導觀眾關注重點
- 人物形象沒有走形
顛覆性結論:Tim 過去認為「AI 生成素材、剪輯師來剪」,但現在認識到——
這種模型一旦成熟,將來是不需要剪輯師的。它沒有篩選或者廢片的概念,所有東西都是有用的。只要生成的分鏡夠好,我為什麼需要剪輯?
你怎麼確定你差的這幾幀、你的思考,比 AI 差的這幾幀更好?尤其是它可以給你無數個版本,而且很快就能給你。
痛點三:音畫匹配度
過去 AI 配音很假。Seedance 2.0 生成的圖書館場景中,人物說「我們現在在圖書館,需要小聲一點」,語音 + 環境音 + 音樂自然混合。過去做音效混音需要人工一天以上,現在一鍵完成。
最恐怖的發現:聲音與身份識別
聲音克隆實驗:只上傳了 Tim 的一張臉部照片,沒有給任何聲音文件或提示詞,Seedance 2.0 自動用 Tim 的真實聲音說話。

空間記憶:上傳影視颶風辦公樓的正面照片,AI 在運鏡中轉到了樓的另一面,且與真實建築吻合。

這基本上可以確定一件事情,就是 Seedance 2.0 很大量地訓練了我們公司的視頻。
Tim 個人沒有收過錢,也沒有被聯繫過授權。平台用戶協議裡可能隱藏了授權條款。
AI 進步速度的案例對比
| 時間 | 製作方式 | 效果 |
|---|---|---|
| 2022-2023 | 手工製作列車飛天鏡頭 | 數十到上百小時 |
| 2023 年 AI | AI 生成 | 幾分鐘,效果差 |
| 2025 年中 AI | AI 生成 | 已經相當強 |
| 2026 年 Seedance 2.0 | AI 生成 | 品質再次飛躍 |

最終判斷
它還不算真正改變視頻行業的 AI,我打心底裡說是這樣。但是即將登場的下一個 AI、下一個版本,可能就是了。
我的想法
- 這是從影視從業者視角出發的判斷,比純技術分析更有說服力——他們是直接感受到衝擊的人
- 聲音克隆和空間記憶的發現,揭示了一個更深層的問題:公開數據 = 訓練數據,創作者無法控制自己的形象被如何使用
- Tim 對剪輯師角色的反思值得深思:不是「AI 替代某個環節」,而是「整條流程被一體化取代」
- 進步速度的案例對比非常直觀:2022 年花上百小時做的事,2026 年 AI 幾分鐘做得更好
衍生的永久筆記
- AI 影片生成的三個關鍵突破
- 公開創作即訓練數據的隱私困境
- AI 取代的是流程而非環節