I Created the Same Animation in Every AI Video Generator
摘要
Futurepedia 用相同 prompt 測試 9 款 AI 影片生成器,涵蓋 18 個挑戰(9 個 text-to-video + 9 個 image-to-video),並用 S/A/B/C/D 五級制評分。這是目前涵蓋模型數量最多的橫向比較。結論:Veo 3.1 是整體最強的模型,但 Grok Imagine 的表現出乎意料地好。
重點筆記
測試的 9 款模型
Veo 3.1、Kling 2.6、Sora 2、Grok Imagine、Runway Gen 4.5、Hailuo 2.3、Wan 2.6、Seedance 1.5、LTX 2.0
Text-to-Video 排名(Tier List)

- S 級最多:Sora 2 在 text-to-video 中 S 級最多,表現最一致
- A 級穩定:Kling 2.6、Veo 3.1 穩定在 A 級以上
- D 級最多:LTX 2.0 多次生成失敗,是最弱的模型
Image-to-Video 排名
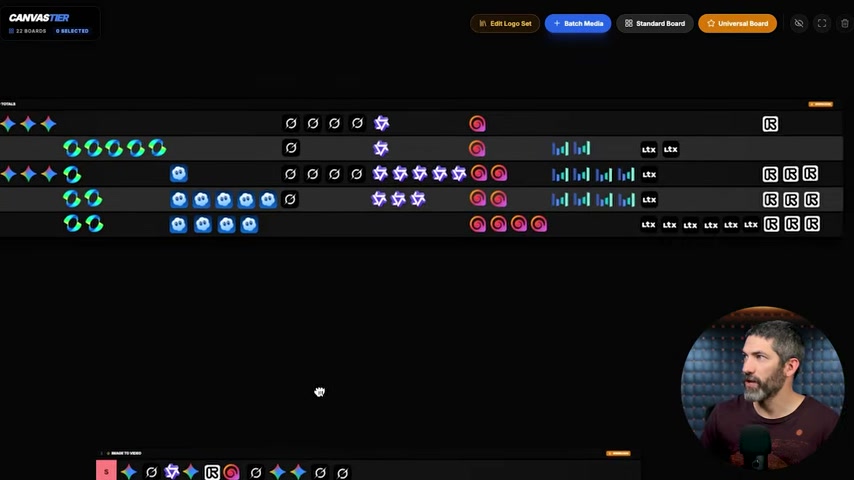
- Veo 3.1 在 image-to-video 中壓倒性勝出——細節保持、風格傳承最好
- Grok Imagine 意外強勁:在複雜場景(章魚酒保、獅蠍獸戰鬥)中表現出色
- Veo 3.1 和 Grok 的總分相同,但 Veo 3.1 在細節和風格傳承上更勝一籌
各模型特長
| 模型 | 最擅長 | 弱點 |
|---|---|---|
| Veo 3.1 | 整體最強,複雜場景、風格保持 | 無明顯弱點 |
| Sora 2 | Text-to-video S 級最多、物理模擬 | 文字渲染(生成亂碼而非可讀文字) |
| Grok Imagine | 複雜 prompt(章魚酒保、獅蠍獸) | 新模型,穩定性待驗證 |
| Kling 2.6 | 文字渲染、穩定 A 級 | 複雜場景稍弱 |
| Runway Gen 4.5 | 舞蹈/編舞(S 級) | 部分 prompt 生成失敗 |
| Hailuo 2.3 | 質感和細節渲染 | 僅一次 S 級 |
| Wan 2.6 | 特定 prompt 表現好 | 整體一致性差 |
| Seedance 1.5 | 偶爾有趣 | 整體 C 級 |
| LTX 2.0 | — | 最弱,多次失敗 |
關鍵挑戰範例

章魚酒保挑戰:要求章魚用獨立觸手調酒,背景有龍飛過城市天際線。測試多步驟複雜指令的執行能力。
核心發現
- Text-to-video 和 Image-to-video 排名完全不同——擅長一項不代表擅長另一項
- Grok Imagine 是最大黑馬——新模型立即躋身頂級
- Sora 2 的文字渲染是盲點——生成的文字是亂碼,而非可讀文字
- Runway 在舞蹈/動作類壓倒性勝出——特定用例的最佳選擇
我的想法
- 擴展了 AI 影片生成器的評測維度 的範圍:Dom 的比較是 4 模型 × 20 prompt(不評分),Futurepedia 是 9 模型 × 18 挑戰(分級評分)。兩者互補——Dom 提供 prompt 設計參考,Futurepedia 提供可操作的排名
- text-to-video ≠ image-to-video 的發現很重要:選擇模型時必須先確定自己的工作流是哪一種,不能只看「整體排名」
- Sora 2 的文字渲染問題呼應了 Seedance 2.0 的亂碼文字問題——這可能是當前整個 AI 影片生成領域的共同短板
- 9 模型中沒有絕對贏家再次印證:AI 影片生成器的選擇必須根據具體需求